
I’ve recently started on a very exciting new collaboration with the I.Sicily project, which is building a fully searchable, freely available online corpus of the inscriptions of Sicily. (In my head I keep turning this project into “I, Sicily” in the manner of “I, Claudius” – this sounds quite dramatic, so I’m sticking with it.)
To quote Jonathan Prag, writing on the I.Sicily website:
I.Sicily is a project to create and make freely available online the complete corpus of inscriptions from ancient Sicily. The project includes texts in all languages (Greek, Latin, Phoenician/Punic, Oscan, Hebrew, and Sikel), from the first inscribed texts of the Archaic period (7th-6th centuries BC) through to those of late Antiquity (5th century AD and later). In the first instance the project is restricted to texts engraved on stone, but it is intended to expand that coverage in the future. The project uses TEI-XML mark-up, according to the EpiDoc schema.
Sicily is traditionally viewed as the ‘crossroads of the Mediterranean’, a ‘cultural melting pot’, and the epigraphic evidence is particularly important for the study of those cultural interactions and the history of the island. However, the epigraphy of ancient Sicily presents significant challenges for those wishing to study it: the existing major collections of Greek (Inscriptiones Graecae XIV) and Latin (Corpus Inscriptionum Latinarum X) are very antiquated (1893 and 1888), and contain a limited amount of information about the texts which they record; subsequent publication of new and existing material has been extremely uneven and widely scattered. A limited number of museum catalogues (Palermo, Catania, Termini Imerese, Messina) and specialist corpora (e.g. IGDS I-II) have improved the situation, but a unified and up-to-date corpus, across all languages, with translations, images and detailed object records, has long been a desideratum.
I. Sicily aims to address these challenges through the creation of an EpiDoc digital corpus, freely available online. The site also aims to provide a focal point for the study of Sicilian epigraphy in general. The project is currently funded by the University of Oxford and hosted by the Faculty of Classics. […] As part of the conversion from MS Access into EpiDoc, the core dataset is being improved and enriched, both by the normalisation of dating and bibliographic records (the full bibliography will be made public in Zotero), and by the incorporation of URI information to enable linked data: places are being linked to Pleiades records (and we are actively working with Pleiades to improve Sicilian topographical data); several categories of metadata are being aligned with the new EAGLE vocabularies; and all our records are being given unique identifiers in Trismegistos.
My contribution is limited to the Oscan inscriptions from Messina, which I’ve worked on before in my book. So, I know the material fairly well – but the EpiDoc TEI XML markup used by the project is fairly new to me. This way of marking up epigraphic and papyrological texts is used by more and more digital humanities projects, and I’d been thinking of learning it for a while. So when Jonathan Prag got in touch to ask if I was interested in collaborating on the project, it seemed a perfect opportunity to learn.
So my task is to take these inscriptions:




and turn them into an XML file which includes the findspot, material, date, past history, previous scholarship, details of the text, alternative readings – basically anything and everything about the inscription that someone might find useful or could want to search for. The beauty of this way of putting things together is that other people will be able to lift the data for whatever they want to know, and build new corpora, maps and other tools. They should also be able to combine this corpus with others very easily, because they will all have been marked up in the same way.
So, for a few days, my computer screen looked something like this:
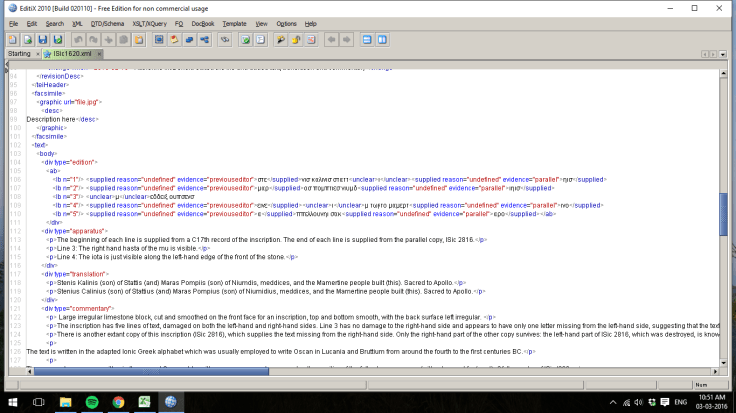
It looks a bit daunting at first, but it’s not too hard to start teaching yourself, especially if you’ve ever used a bit of HTML before. I was helped out a lot by all the existing online resources for beginners, such as the “Gentle Introduction to Mark-Up for Epigraphers” and a handy tool which converts plain text into EpiDoc. A good XML editor is a must too – I was just using a free programme called EditiX, but the editor takes a lot of the guess-work out (normally by shouting “There is an error!” in big red letters, and then kindly explaining the nature of the error to you). It took a while for me to get going, but I found it pretty satisfying when I felt I’d cracked the code.
An initial version of the I.Sicily corpus should be up and running in a few months time. Until then, you can find out more about the I.Sicily project and its aims here, read blog posts from Jonathan Prag here and follow them on twitter over here. There’s also a free EpiDoc training session (which I hope I’ll be attending) at the Institute of Classical Studies 11-15 April, should you be interested in learning more.


Leave a comment